ich denke seit einiger Zeit darüber nach, wie man den Straßenverkehr optimieren kann, in dem man die Ampeln durch ein KNN steuern lässt.
Dazu folgendes wunderbares, selbstgezeichnetes Bild:

Fall 1)
Autobahn. Blockabfertigung mit Ampel
Fall 2)
Hauptstraße mit Seitenstraße als Einschleusung auf Hauptstraße. Ebenfalls Ampel.
Fall 3)
Same same. Hier nur mal die Komplexität. Die Entscheidung an der vorderen Ampel kann Auswirkungen auf die hinteren Entscheidungen haben, bzw. auf den Gesamtdurchsatz der durch diese Entscheidung beeinflusst wird. Das Auto mag vielleicht den Durchsatz an dem Punkt des Motorrads erhöhen, stopft aber die Straße so voll, dass es Rückstau gibt und es eine Kettenreaktion auslöst. Hier wäre es ggf. im Sinne der Blockabfertigung sinniger zu warten und die Straße etwas frei werden zu lassen.
Ich sehe das Problem ähnlich gestaltet wie die optimierte Strategiefindung bei Brettspielen. Daher habe ich auch den Thread über Kniffel (viewtopic.php?f=5&t=231) gerne gelesen. Leider sind da die Dateien nicht mehr verfügbar.
Ist mein folgender Ansatz korrekt?
Jede Ampel für sich besteht aus zwei potentiellen Aktionen: Rot oder Grün.
Als Eingangsneuronen benötige ich also die Aktion und den Zustand des Straßenverkehrs. Was genau ist dieser Zustand? Interessant ist doch nur der Füllgrad bestimmter Strecken und somit implizit die Anzahl der Fahrzeuge.
Als Ausgangsneuron gibt es nur eines mit der Wertigkeit der Aktion.
Ist es damit möglich eine optimale Ampelsteuerung zu erzeugen? Jede Entscheidung ist so minimal, kann aber Einfluss auf das Ergebnis am Ende haben. Was optimiert werden soll ist eben der Durchsatz pro Stunde. Durch eine falsche Entscheidung einer bestimmten Ampel, kann der Durchsatz nach vielen Minuten anfangen zu sinken.
Wie bringt man soetwas in ein RL System ein? Mir fehlts da noch ein bissl am gesamten Zusammenhang. Kann mich jemand auf den richtigen Pfad bringen? Wie sehr lässt es sich mit dem Kniffel-Beispiel vergleichen?
EDIT:
Ich habe mal das Beispiel 1 (Blockabfertigung) in einem KNN abgebildet:
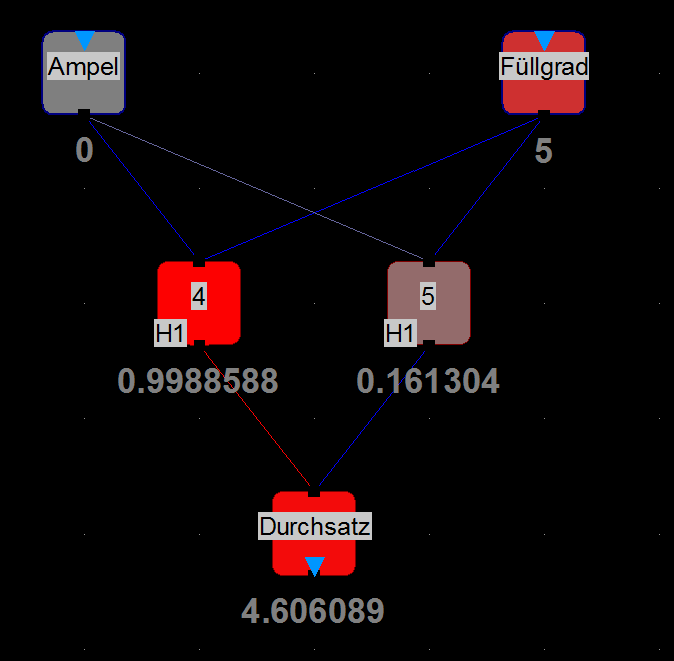
Eingangsneuron Ampel bekommt Werte [0;1] für Rot oder Grün
Eingangsneuron Füllgrad bekommt Werte [0;1;2;3;4;5;6;7] für die Anzahl an Fahrzeugen auf der Strecke nach der Ampel
Als Ausgangsneuron habe ich den Durchsatz angegeben.
Meine Trainingsdaten sehen wie folgt aus:
Ampel;Füllgrad;Durchsatz
0;5;5
1;5;3
0;6;3
1;6;3
0;2;2
1;2;3
0;4;4
1;4;5
1;1;2
0;0;0
0;3;3
0;7;3
1;7;3
0;8;3
1;8;3
Damit bekomme ich erstmal recht sinnvolle Ergebnisse.
Durchsatz bei Ampel 0 und Füllgrad 4: 4,20
Durchsatz bei Ampel 1 und Füllgrad 4: 4,62
Durchsatz bei Ampel 0 und Füllgrad 5: 4,6
Durchsatz bei Ampel 1 und Füllgrad 5: 2.99
Das sind natürlich zu wenige Daten und man könnte mit den Anzahl der hidden Neuronen spielen, aber ich denke die passen so erstmal. Zu viele sollten es nicht sein, sonst lernt das NN einfach nur auswendig.
Macht das ganze so Sinn? Kann man das nun auf komplexere Beispiele übertragen? Da muss ich noch mal darauf rumdenken. Idee sollte sein alle anderen Teilstrecken-Füllgrade als Eingangsneuronen mit anzulegen. Damit braucht man aber auch viel mehr Trainingsdaten.
Grundidee eines fertigen Algorithmus sollte sein: Lege alle Füllgrade der jetzigen Situation an und lasse das Netz zweimal durchlaufen. Einmal mit Ampel 0 und einmal mit 1. Der höchste Durchsatz gewinnt (mit Wahrscheinlichkeit um die 10% ein zufälliges Ergebnis zu wählen).
Was mir nur nicht ganz klar ist: Wie komme ich denn an die Trainingsdaten? Wie kann ich denn wissen was der Durchsatz pro Stunde ist, wenn davon sehr viele Entscheidungen abhängen und eben nicht nur die eine. Es ist ja nicht so, dass ich die eine Entscheidung treffe und dann extern die Fahrten simuliere und am Ende einen konkreten Durchsatz bekomme. Die Entscheidung Autos einzuschleusen oder die Blockabfertigung zu aktivieren oder deaktivieren treffe ich ja permanent.
Das muss doch das System irgendwie selber machen. Ich kann mir das nur so erklären, dass der am Ende erlangte Durchsatz gar nicht bestimmt werden kann sondern einfach nur als zusätzlicher Eingang anliegt und einfach den Durchsatz für genau den aktuellen Zustand angibt.
Wie lernt dann das System von seinen eigenen Entscheidungen die ja direkten Einfluss auf den Durchsatz haben? Wo existiert hier der Rückfluss?
EDIT 2:
Weiter gehts. Wieder was gelernt:
Trainingsdaten sollten selbst erstellt werden. Stichwort unsupervised learning (sofern korrekt in den Kontext gebracht).
Dazu folgende Formel: Inputs = [s, a], Output = Q(s, a) + alpha * [r +gamma * Qmax(s', a') - Q(s, a)]
Der entsprechende Wert wird als Wert für das Ausgangsneuron gesetzt und das Pattern abgelegt.
Dazu folgender Text:
Jetzt ist nur die Frage was man als Belohnung r annimmt. Da bin ich noch nicht sicher. Der aktuelle Durchsatz? Aber der wird unter Umständen viel weiter hinten bestimmt und somit hätte die aktuelle Aktion keinen sofortingen Einfluss darauf. Könnte es dennoch funktionieren, da einfach alle Rewards versetzt sind? Das müsste doch dann negative Auswirkungen auf die Bewertung der jeweiligen Neuronen haben. Ideen?Re: "Richtige" Netzarchitektur für das Spiel KNIFFEL ?
Postby Admin » Thu 3. Nov 2011, 22:31
Also, ich beginne mal mit einer Wiederholung des Ablaufs, den ich in dem anderen RL-bezogenen Thread gepostet habe.
Einige kleine Präzisierungen bzgl. der Bezeichner habe ich vorgenommen. Außerdem habe ich noch den Parameter 'alpha' (=Schrittweite) eingeführt, er ist in der klassischen RL-Literatur vorgesehen. Man kann ihn auf 1 setzen, dann kommt wieder das raus, was ich vereinfachend im anderen Thread geschrieben hatte. Es macht aber bestimmt Sinn, diese Schrittweite alpha (als Konstante) in die Implementierung aufzunehmen, dann hat man noch einen weiteren Parameter zum Experimentieren.
- Der Agent legt im momentanen Zustand s für jede darin mögliche Aktion a den Input (momentaner Zustand s, Aktion a) an das Netz an an und holt sich aus dem Netz den Output Q(s, a).
- Mit einer gewissen Wahrscheinlichkeit führt der Agent die Aktion mit dem höchsten Output Qmax(s, a) aus ('Exploitation'). Mit der Restwahrscheinichkeit führt der Agent stattdessen eine zufällig gewählte Aktion aus ('Exploration'). Die ausgeführte Aktion a wird gemerkt (im Speicher gehalten).
- Der Agent erreicht dadurch einen neuen Zustand s' und erhält eine Belohnung r. Achtung: 'Belohnung' kann auch ein negativer Wert sein.
- Der Agent legt im neu erreichten Zustand s' wieder für jede mögliche Aktion den Input (s', a') an und holt sich aus dem Netz den Output Q(s', a').
- Der Wert der höchstwertigen Aktion Qmax(s', a') wird gemerkt:
- Ein neues Trainingsmuster wird abgelegt und zwar für Inputs = [s, a], Output = Q(s, a) + alpha * [r +gamma * Qmax(s', a') - Q(s, a)], wobei alpha und gamma zwischen 0 und 1 gewählt werden.
- Das neue Trainingsmuster wird dem bereits erarbeiteten Fundus von Trainingsmustern hinzugefügt und über alle Trainingsmuster ein Trainingsschritt durchgeführt (= 1x Teach Lesson)
- Ist die maximale Größe des Trainingssatzes erreicht (z.B. 50000 Muster), dann wird das älteste Muster vom Trainingssatz gelöscht.
- Das Ganze beginnt von vorne
Der Faktor 'gamma' führt dazu, dass der Agent nicht nur den erzielten momentanen Gewinn r erlernt, sondern auch noch den (geschätzten) nächsten zu erreichenden Gewinn Qmax(s', a') mit einbezieht. So pflanzt sich erzielter und zu erwartender zukünftiger Gewinn durch die Zustands-/Aktionspaare zurück fort. Ein höherer Wert von Gamma (Richtung 1) macht den Agenten 'weitsichtiger'. Ein niedriger Wert von Gamma führt dazu, dass der Agent mehr auf kurzfristige Gewinnerzielung trainiert wird.
Zu Beginn des Trainings sollte viel Exploration (also 'ausprobieren') stehen. Je schlauer der Agent wird, um so mehr kann man auf Exploitation (also Ausnutzung von erlerntem Wissen) umsatteln.
(Quelle: viewtopic.php?p=973#p973)